이번 포스팅에서는 Error Detection과 그에 대한 Correction에 대해서 알아 볼 예정이다.
# 1. Types of Errors
먼저 에러의 타입에 대해서 알아 보자.
한 점에서 다른 점으로 비트가 흐를 때, 간섭으로 인해 예측할 수 없는 변화가 발생할 수 있다. 이러한 간섭은 신호의 형태를 변경할 수 있는데 단일 비트 오류(single-bit error)란 주어진 데이터 단위(예: 바이트, 문자 또는 패킷) 중 하나의 비트만 1에서 0 또는 0에서 1로 변경된 것을 의미한다. 반면 버스트 오류(burst error)는 데이터 단위 내에서 2개 이상의 비트가 1에서 0 또는 0에서 1로 변경된 것을 의미한다.
다음의 예시를 살펴 보자.
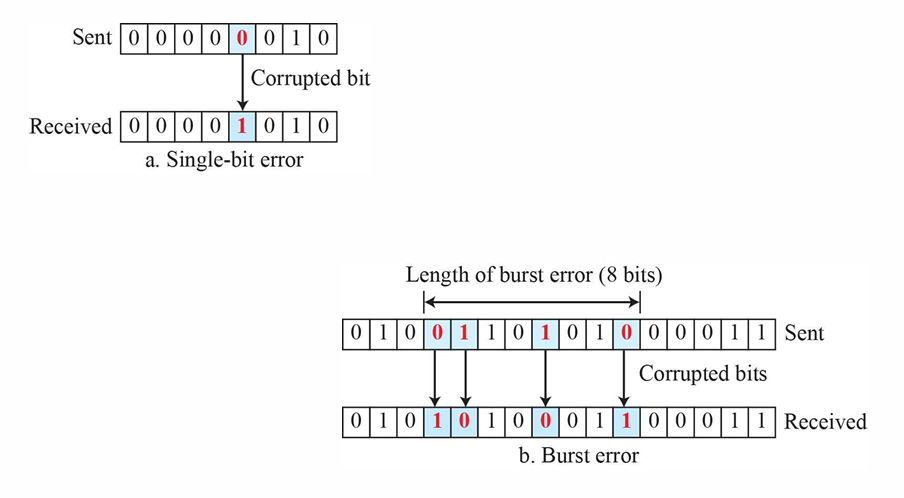
좌측 상단의 에러를 살펴 보면 Sent 데이터 중에서 하나만 잘못 전송되어서 Received 데이터가 변경되었다.
그에 반해 우측 하단의 에러를 살펴 보면 Sent 데이터 중에서 잘못 전송된 데이터의 양쪽 끝 사이의 거리를 계산했고 에러 데이터는 Received 데이터에 반영되었다.
# 2. Redundancy
오류를 감지하거나 수정하기 위해서는 데이터와 함께 일부 추가 비트를 전송해야 한다. 이러한 여분의 비트는 발신자에 의해 추가되고 수신자에 의해 제거된다. 이들의 존재로 인해 수신자는 손상된 비트를 감지하거나 수정할 수 있다. 이러한 추가 비트를 우리는 "중성(redundancy)"이라고 한다.
## 2-1 Detection and Correction
오류 수정은 오류 감지보다 어렵다. 오류 감지에서는 오류가 발생했는지 여부만 확인하면 되기 때문이다. 심지어 손상된 비트의 수에도 관심이 없고 단일 비트 오류와 버스트 오류는 에러 그 자체로 동일하다. 그러나 오류 수정에서는 손상된 비트의 정확한 수를 알아야 하고 더 중요한 것은 메시지 내에서 그 위치를 알아야 한다.
여러 가지 부호화 체계를 통해 여분의 비트를 추가하여 중복성을 달성할 수 있다. 송신자는 여분의 비트와 실제 데이터 비트 사이의 관계를 생성하는 과정을 통해 여분의 비트를 추가한다. 수신자는 오류를 감지하기 위해 두 세트의 비트 간의 관계를 확인한다. 여분의 비트와 데이터 비트의 비율 및 프로세스의 견고성은 모든 부호화 체계에서 중요한 요소이다.
## 2-2 Block Coding
블록 부호화는 메시지를 일정한 크기의 블록으로 나눈 다음, 각 블록에 여분의 비트를 추가하여 오류를 검출하거나 수정하는 방법이다.
이 과정에서는 주로 패리티 비트, 해밍 코드 등의 방법이 사용된다. 이렇게 생성된 부호어는 오류를 검출하고 필요한 경우 수정하는 데 사용된다. 이러한 방식은 데이터 통신에서 신뢰성을 높이는 데 도움이 된다.
조금 자세한 과정을 알아 보자.
- 블록 부호화에서는 메시지를 k 비트씩의 블록, 즉 데이터 워드로 나눈다.
- 각 블록에 r 개의 여분 비트를 추가하여 길이가 n = k + r이 되도록 한다.
- 그 결과로 나오는 n 비트 블록을 부호어라고 하는데 추가된 r 비트는 어떻게 선택되거나 계산되는지에 대한 것이다.
## 2-3 Error Detection
블록 부호화를 사용하여 오류를 감지하는 방법은 다음과 같다. 수신기가 다음 두 가지 조건을 충족하는 경우 원래의 코드워드의 변경을 감지할 수 있습니다.
- 수신기는 유효한 코드워드 목록을 가지고 있거나 찾을 수 있다.
- 원래의 코드워드가 유효하지 않은 코드워드로 변경되면 수신기는 받은 코드워드가 유효하지 않음을 감지하고, 이를 통해 오류가 발생했음을 알 수 있다. 예를 들어, 해밍 코드는 이러한 오류 감지 기능을 제공하는데, 이를 통해 코드워드 간의 거리를 계산하여 오류를 검출한다.
